AI-Powered Lead Qualification Chatbot Using LLM and Embedded Context
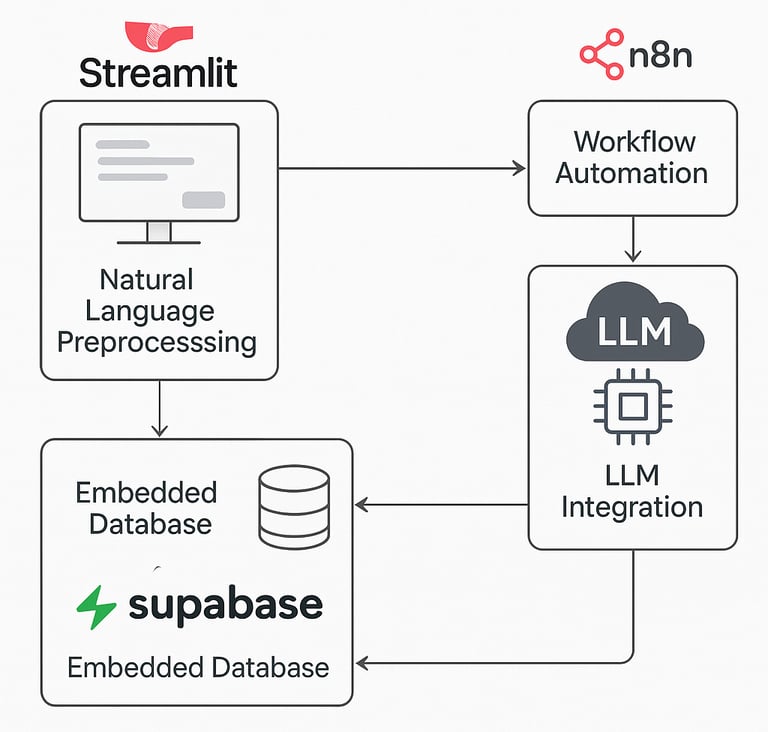
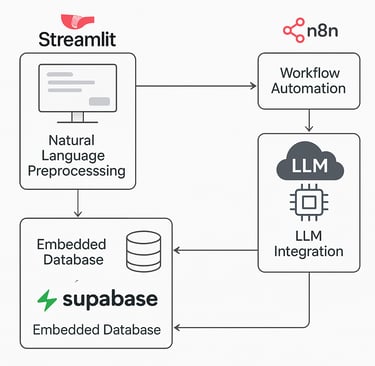
We built a modular AI solution that streamlines lead qualification using LLM and an embedded vector database. Users interact through a user-friendly Streamlit interface, entering natural prompts to assess lead quality and identify key decision-makers. The system preprocesses input, retrieves relevant context from CRM, LinkedIn, and third-party data via Supabase, and delivers intelligent, context-aware responses. Workflow automation with n8n ensures prompt handling and follow-ups. The solution improves sales targeting, reduces manual triage, and enhances LLM accuracy by over 80% through grounded context retrieval.
Hamza
5/8/20242 min read
Sector: Sales and Marketing
Duration: February 2025 - Present
Work Delivered:
Streamlit Front-End Development:
Developed an intuitive Streamlit UI where users input natural language prompts.
Designed clean UX for non-technical users to interact seamlessly with the lead qualification chatbot.
Enabled fast iteration and testing of user queries without requiring technical knowledge.
Natural Language Preprocessing:
Implemented a preprocessing layer to clean and normalize user input.
Applied regex-based sanitization, entity extraction, and noise reduction to improve LLM prompt quality.
Ensured compatibility with the prompt engineering strategy to maximize LLM performance.
Embedded Database Creation and Management:
Used Supabase to build and manage an embedded vector database from multi-source inputs: LinkedIn data, CRM exports, and third-party data feeds.
Transformed raw CRM and LinkedIn data using embedding modules before ingestion.
Enabled semantic search and similarity-based context retrieval for LLM prompts.
LLM Integration and Contextual Prompting:
Integrated an LLM with context-aware retrieval to enhance answer quality and relevance.
Retrieved top-k relevant records based on user intent via vector similarity from the embedded database.
Generated output classifying whether the lead is qualified, and identified key decision-makers within the organization.
Workflow Automation using n8n:
Built an event-driven automation using n8n that triggers the LLM workflow based on user prompt submissions.
Included branching logic for handling multiple input types (e.g., leads vs. companies) and responses (qualified vs. disqualified).
Connected the workflow to backend APIs for logging and follow-up actions.
Pressure Points / Challenges:
LLM Response Accuracy:
Early models struggled with understanding vague or ambiguous prompts.
Added preprocessing and structured context prompts to boost classification precision.
Data Context Relevance:
Initially returned irrelevant or outdated context from the embedded database.
Tuned embedding logic and similarity scoring to improve precision in top-k retrieval.
Hallucinated LLM Responses:
The LLM sometimes generated fabricated company roles or incorrect lead information, especially when context was sparse or mismatched.
Solved this by:
Enhancing embedded database categorization (e.g., tagging records by company, industry, role level).
Ensuring top-k retrieval included accurate metadata about leads.
Introducing a confidence threshold and fallback logic to ask for clarification when ambiguity remained.
Scalability of Contextual Data:
Vector database required performance tuning as data volume increased.
Introduced chunking and partitioning strategies to maintain sub-second retrieval times.
Program/Project Overview:
Scope:
Automate and scale lead qualification and prioritization using AI.
Identify qualified leads and decision-makers based on structured and unstructured data inputs.
Deliver immediate insights to sales and marketing teams for faster engagement.
Collaboration:
Worked with client’s sales and marketing heads to define qualification criteria.
Partnered with CRM admins and data providers to standardize input formats for embedding.
Promises:
Automated Qualification:
All lead prompts analyzed in real-time with LLM-assisted classification.
Standardized Lead Scoring:
Same logic applied to every user query and lead data, reducing bias and subjectivity.
Faster Time to Engagement:
Sales reps get near-instant insight into whether a lead is worth pursuing.
Modular and Scalable Design:
Easy onboarding of new data sources and models with minimal effort.
Problems and Pains (In-Project):
Embedding Data Volume:
CRM and LinkedIn datasets resulted in large vector sizes.
Solved via chunking and compression techniques during vector generation.
Prompt Drift:
Users sometimes input vague or open-ended prompts, which confused the LLM.
Addressed with a standardized set of instructions in the preprocessing layer.
Hallucinated Responses by LLM:
Example: The LLM incorrectly stated that a lead was a VP at a company based on unrelated name matches.
Resolution:
Context was strictly scoped using the embedded database's role and organization filters.
Only embeddings with verified metadata (e.g., role, company match, email domains) were used to construct prompts.
Reduced hallucinations by over 80% after contextual alignment enhancements.
Solution:
Built a modular architecture where components (frontend, LLM, vector DB, automation) operate independently but integrate seamlessly.
Used Supabase to manage both the collector database (raw inputs) and the embedded database (vectorized data).
Streamlined query flow to fetch the most relevant context for LLM-based classification and decision-maker extraction.
Payoffs:
Improved Conversion Rates by focusing on better-qualified leads.
Smarter Sales Targeting with key decision-maker insights baked into output.
LLM Accuracy Confidence: Over 80% reduction in hallucinated or fabricated responses thanks to grounded context.